AI-assisted development is all the rage nowadays. I'm sceptical, but really want to give these tools a fair shot. But then I look at what these tools actually manage to do, and am disillusioned: these tools can be worse than useless, making us net-negative productive.
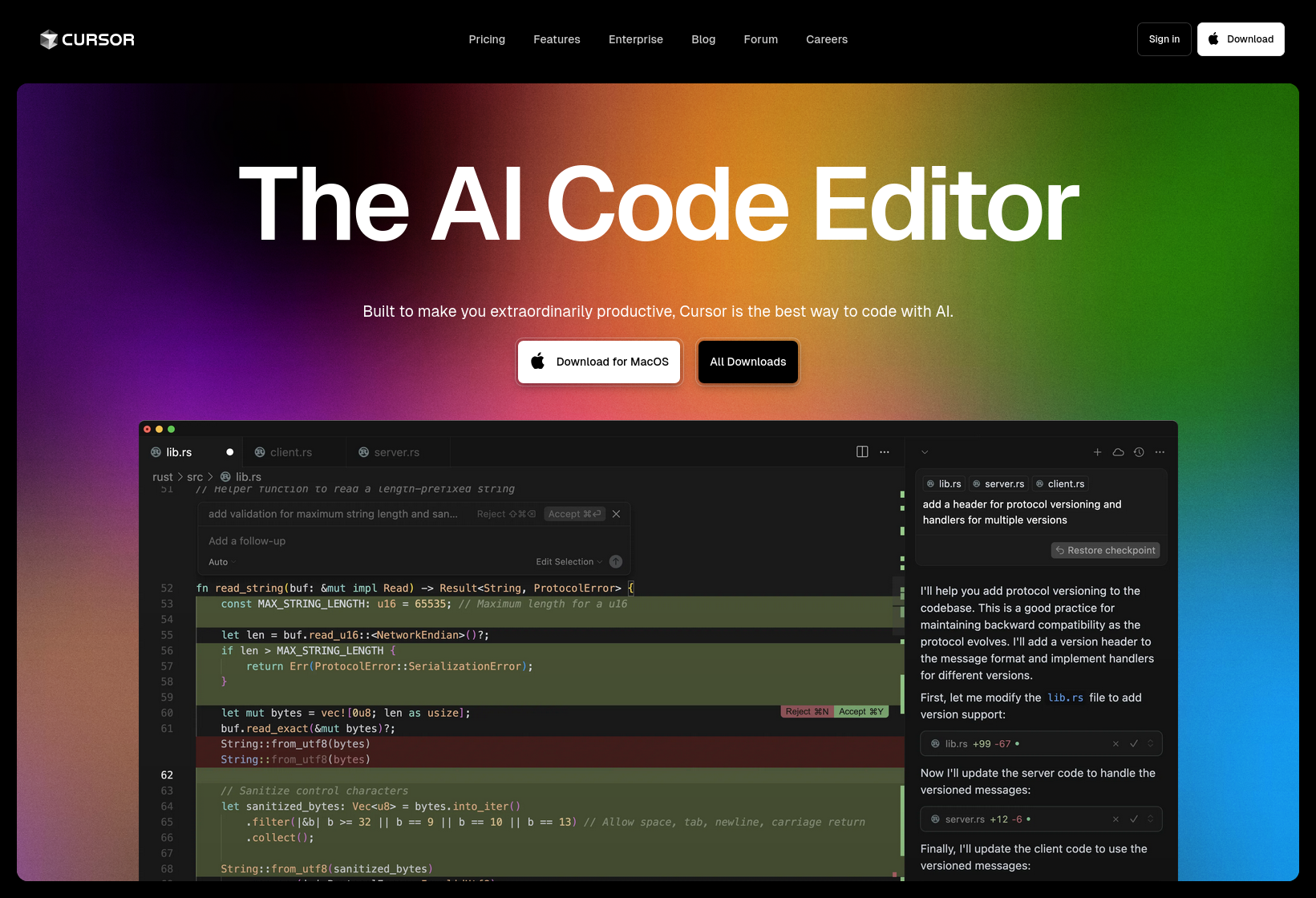
Let's pick one of the best possible examples of AI-generated code changes. An example so good, that the Cursor Editor uses it to advertise on their front page.
What Cursor thinks great code looks like
Here's the homepage of the Cursor Editor website, at the time of writing:
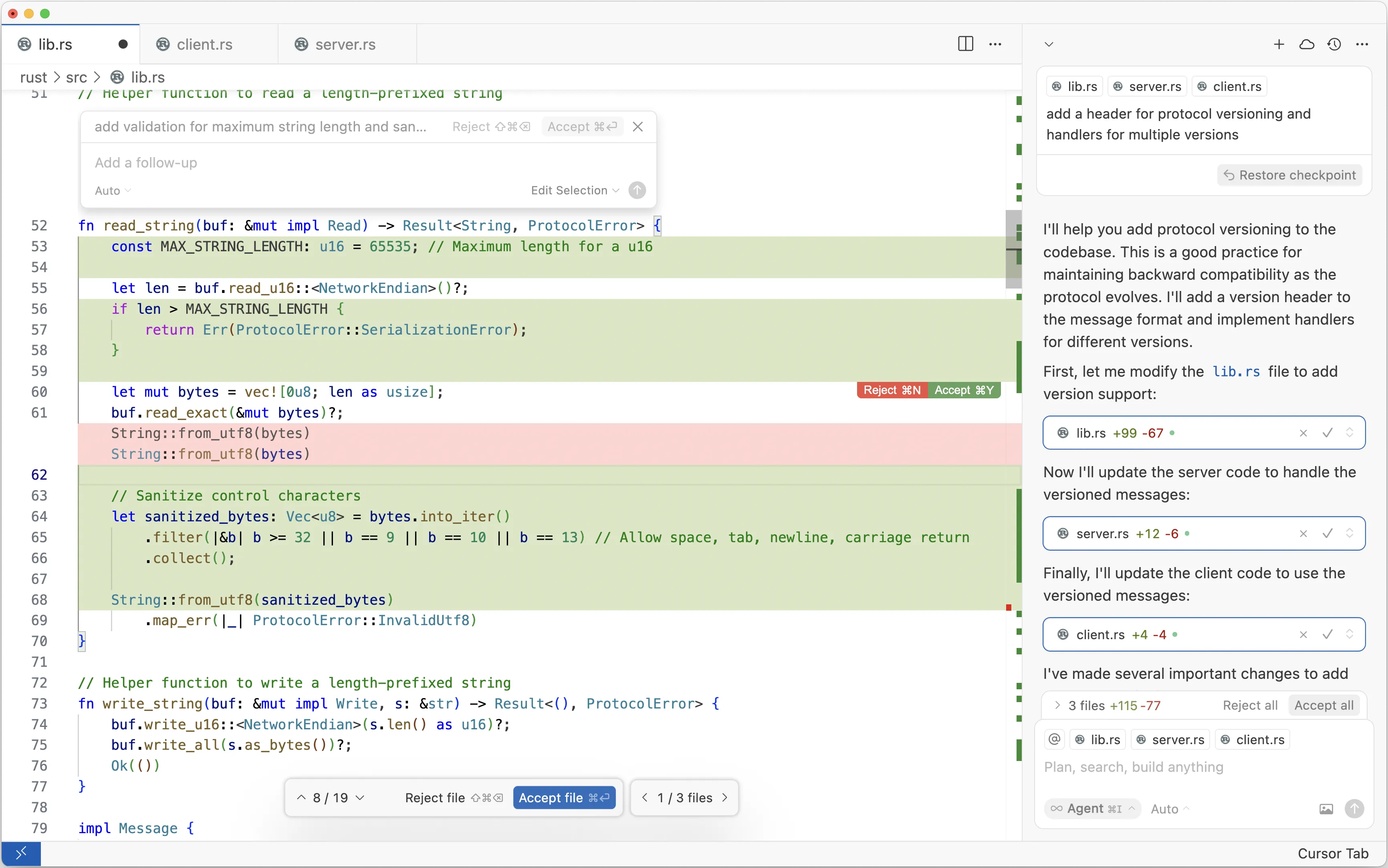
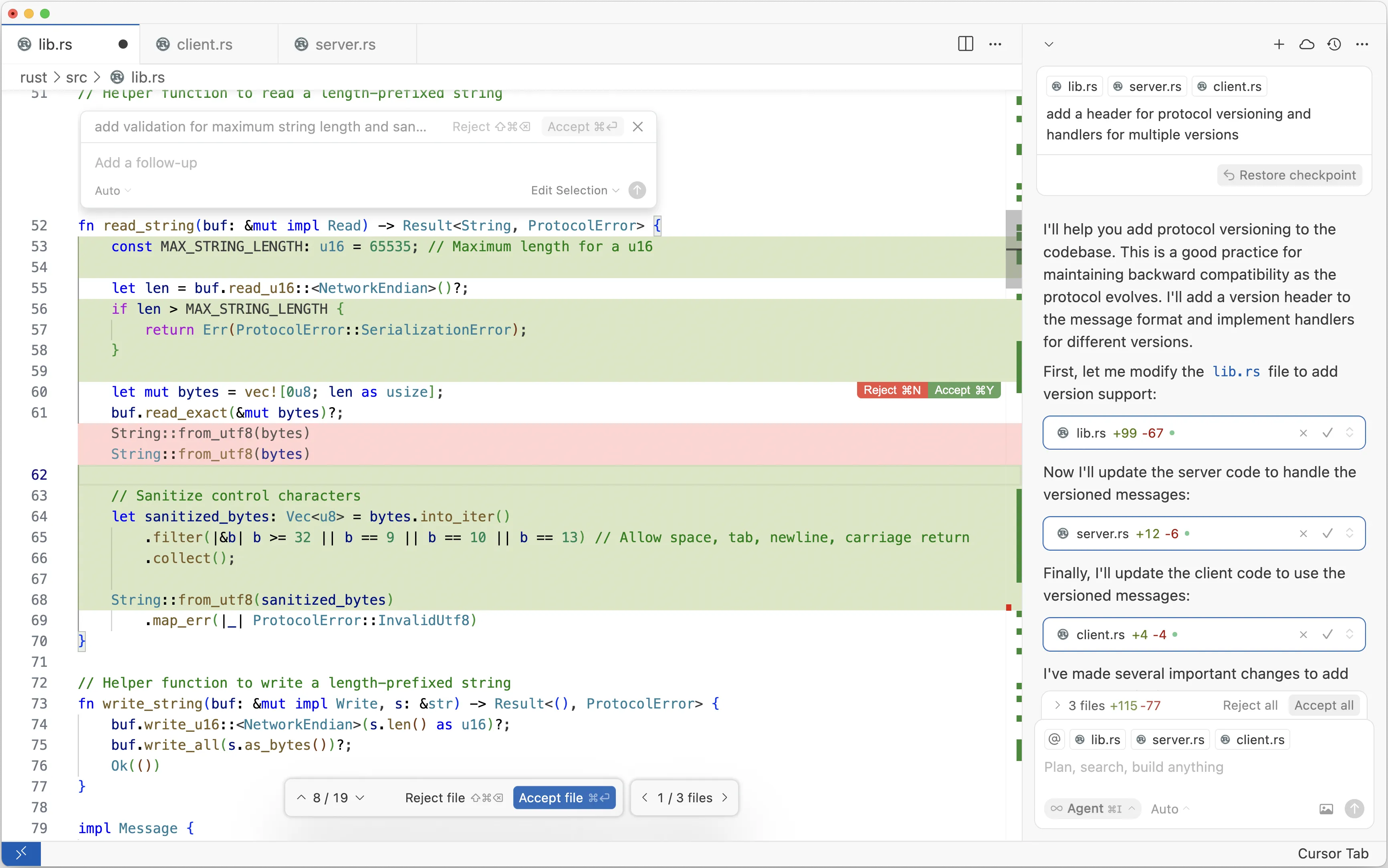
We can look at just the screenshot of the editor, using the Light Mode variant for legibility:
sources
- https://www.cursor.com/ as of 2025-05-29. archived link.
- live link to hero image as of 2025-05-29. archived link
{kind=link}
{kind=link}
The image shows a screenshot of the Cursor IDE, with a pending AI suggestion for a code change. The code is a function written in Rust for reading a length-delimited string from some binary protocol.
Transcription of the code before the change:
fn read_string(buf: &mut impl Read) -> Result<String, ProtocolError> {
let len = buf.read_u16::<NetworkEndian>()?;
let mut bytes = vec![0u8; len as usize];
buf.read_exact(&mut bytes)?;
String::from_utf8(bytes)
.map_err(|_| ProtocolError::InvalidUtf8)
}
The suggestion is accompanied by a pop-up that says:
add validation for maximum string length and san…
Transcription of the suggested code:
fn read_string(buf: &mut impl Read) -> Result<String, ProtocolError> {
const MAX_STRING_LENGTH: u16 = 65535; // Maximum length for a u16
let len = buf.read_u16::<NetworkEndian>()?;
if len > MAX_STRING_LENGTH {
return Err(ProtocolError::SerializationError);
}
let mut bytes = vec![0u8; len as usize];
buf.read_exact(&mut bytes)?;
// Sanitize control characters
let sanitized_bytes: Vec<u8> = bytes.into_iter()
.filter(|&b| b >= 32 || b == 9 || b == 10 || b == 13) // Allow space, tab, newline, carriage return
.collect();
String::from_utf8(sanitized_bytes)
.map_err(|_| ProtocolError::InvalidUtf8)
}
This looks perfectly reasonable, but is deeply flawed:
- the length validation is completely useless
- the sanitization is dubious
Useless length validation
First, let's focus on this part of the code, where the AI suggested adding all lines other than the existing read_u16() statement:
const MAX_STRING_LENGTH: u16 = 65535; // Maximum length for a u16
let len = buf.read_u16::<NetworkEndian>()?;
if len > MAX_STRING_LENGTH {
return Err(ProtocolError::SerializationError);
}
This is correct, in a sense.
The value 65535 is indeed the maximum number for the u16 type,
though a human programmer would probably have used the equivalent constant u16::MAX instead, which would have made that comment unnecesary.
However, this is the largest value that an u16 can contain.
That means the condition len > MAX_STRING_LENGTH can never be true.
Better tools like Clippy will point this out and warn the programmer:
error: this comparison involving the minimum or maximum element for this type contains a case that is always true or always false
--> src/lib.rs:10:8
|
10 | if len > MAX_STRING_LENGTH {
| ^^^^^^^^^^^^^^^^^^^^^^^
|
= help: because `MAX_STRING_LENGTH` is the maximum value for this type, this comparison is always false
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#absurd_extreme_comparisons
= note: `#[deny(clippy::absurd_extreme_comparisons)]` on by default
So here the AI has generated code that is useless at best, and actually generates compiler warnings due to unreachable code.
A useful AI-driven development tool would have pushed back against the suggestion to add maximum string length validation, and would have explained something like:
Because the string length is read from an
u16, the string can already be at most 65535 bytes long, which is 64KB.Is this OK as-is, or do you want to enforce a lower limit?
Questionable sanitization
Let us continue with the sanitization code. Relevant excerpt:
// Sanitize control characters
let sanitized_bytes: Vec<u8> = bytes.into_iter()
.filter(|&b| b >= 32 || b == 9 || b == 10 || b == 13) // Allow space, tab, newline, carriage return
.collect();
The code mostly does what it says. The numbers do correspond to the characters listed in the comment. There is a small concern that this code operates on bytes rather than on characters. But since UTF-8 is an ASCII super-set, this is close enough.
My main concern is that:
- this isn't very good code, and
- it's not clear that this code is correct, given the application's requirements.
Let's talk about style.
First, the added code involves unnecessary allocations.
It could trivially be modified to an in-place operation by using Vec::retain():
bytes.retain(|&b| b >= 32 || b == 9 || b == 10 || b == 13); // Allow space, tab, newline, carriage return
Second, the comment would be unnecessary if the predicate used character literals instead of decimal numbers, e.g. b'\n' instead of 10.
The code can be reduced to:
bytes.retain(|&b| b >= b' ' || b == b'\t' || b == b'\n' || b == b'\r');
Arguably, the code should not use such literals at all, and should instead use the functions provided by the Rust standard library:
bytes.retain(|&b| !b.is_ascii_control() || b.is_ascii_whitespace());
But this brings us to the second concern, that it's not clear that this sanitization is correct.
-
What exactly is a whitespace character? For example, the AI-suggested code allows
\rcarriage returns, but some (non-Windows) programs consider this to be a regular control character. The aboveu8::is_ascii_whitespace()function treats\fU+000C FORM FEED as a whitespace character. Other programs include\vU+000B VERTICAL TAB as whitespace. -
What about U+007F DELETE? This is clearly a control character by all reasonable definitions, but is positioned at the very end of the ASCII range. Should it not be excluded as well?
-
What about non-ASCII whitespace and control characters? The bytes are decoded as UTF-8 immediately afterwards, and there are various Unicode-specific control characters like paragraph separators, interlinear annotations, or bidi isolates. Arguably, the U+FEFF ZERO WIDTH NO-BREAK SPACE (byte order mark) is a control character in leading position.
There's also the question whether such sanitization is appropriate in a low-level function that reads data from a network stream. Many applications can be agnostic about such details unless the string is used in a specific context (e.g. HTTP header or terminal output). There is also generally no security impact.1 Pre-emptively stripping control characters has the same vibe as trying to thwart SQL injection by removing all quotes from a string.
This might be correct, but it can also break an application.
Here, a consequence would be that the read_string() and write_string() functions no longer mirror each other, which would cause a good test suite to fail.
A useful AI-driven development tool wouldn't just pick one solution, but explain the problem space and let the programmer make an informed choice.
Programming is about decisions
At this point of this article, we're about 800 words into an exegesis of an 8 line diff. There is a lot of hidden complexity even in this simple example.
The AI has suggested a solution, but the added code is arguably useless or wrong. There is a huge decision space to consider, but the AI tool has picked one set of decisions, without any rationale for this decision.
Great programmers can look at the suggested changes, notice the problems, and work backwards. For example, they see the useless string length validation and decide to pick a lower limit instead, or to skip the AI suggestion. However, that generally takes more effort than just writing the code yourself. And many programmers might not notice the problem until perhaps much later.
Programming is about lots of decisions, large and small. Architecture decisions. Data validation decisions. Button color decisions.
Some decisions are inconsequential and can be safely outsourced. There is indeed a ton of boilerplate involved in software development, and writing boilerplate-heavy code involves near zero decisions.
But other decisions do matter.
For this kind of work, it doesn't matter how fast code can be written (or generated). It matters that we arrive at good-enough decisions efficiently.
AI-powered tools can help here if they can independently resolve less important decisions correctly most of the time. And, as a corollary, if they can flag decisions that need additional review. If they can provide the necessary context to make a good decision.
But as of May 2025, that's not what's happening. In this example, the AI has taken suboptimal decisions and has not given us the context to make better decisions.
And this is not a cherry-picked example by me. This is the first thing Cursor shows potential customers to demonstrate how good this AI-powered tooling allegedly is. This example was presumably cherry-picked by the Cursor marketing team to advertise the best of the best of what is possible.
If an AI-powered tool saddles you with useless code, breaks the code by making incorrect decisions, and makes changes so subtly incorrect that 8 lines of diff need 800 words of review and discussion, then this tool doesn't make anyone “extraordinarily productive”. Then, this tool is a net-negative for productivity.
Footnotes
-
To be fair, it does make sense to apply validation and sanitization at component boundaries. Injection attacks remain in the OWASP Top 10, often in connection with common weaknesses like CWE-116 Improper Encoding or Escaping of Output or CWE-138 Improper Neutralization of Special Elements. However, consequent encoding/decoding and use of parameterized APIs tends to be more robust than sanitization-based mitigations. Sanitization is also highly application-specific. One application's sanitization is another application's data corruption. ↩
- next post: Ganzua
- previous post: You Just Don't Need Tox